
#
Auto-Scrolling Webpage Capture to PDF




GitHub: 0xarchit/Scroll-To-Pdf
A desktop application built with PyQt6 that automatically scrolls through a webpage, captures screenshots, stitches them, and exports the result as a multi-page PDF.
#
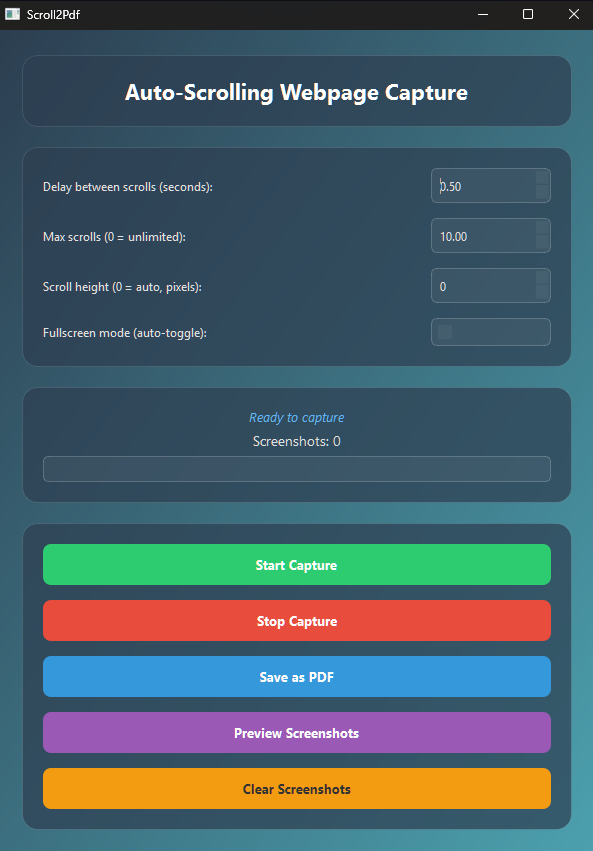
Screenshots
#
Overview
When you need a PDF of an entire webpage (including content below the fold), manual scrolling and screenshotting is tedious. AutoScrollCapturePDF automates:
- Scrolling through the page
- Taking successive screenshots
- Detecting end of page via image similarity
- Concatenating and saving as PDF
Ideal for long articles, reports, dashboards, and documentation pages.
#
Features
- Configurable scroll delay, height, and max scroll count
- Automatic end-of-page detection (image similarity threshold)
- Preview stitched result before export
- Primary and fallback PDF export methods (Pillow and img2pdf)
- Dark-themed, responsive PyQt6 GUI
- Cross-platform (Windows/macOS/Linux)
#
Installation
Clone this repository:
git clone https://github.com/0xarchit/Scroll-To-Pdf.git cd ScreenShotToPdf(Optional) Create a virtual environment:
python -m venv .venv .venv\Scripts\activate # Windows source .venv/bin/activate # macOS/LinuxInstall dependencies:
pip install -r requirements.txtEnsure
app_icon.icosits alongsidemain.pyin the project root.
#
Usage
#
Launching the Application
python main.pyThe main window appears. Adjust settings then click Start Capture.
#
Settings Panel
#
Capture Workflow
- Click Start Capture → 3‑second countdown → window minimizes
- Focus browser and let it scroll+capture automatically
- Status bar displays live updates and screenshot count
- Capture stops on page end or reaching max scrolls
- Window restores with Preview, Save, and Clear options
#
Previewing
Click Preview Screenshots to open a stitched image of all screenshots. Close preview to return.
#
Exporting to PDF
- Click Save as PDF
- Choose destination file path (
.pdf) - Application attempts Pillow export; on failure, uses
img2pdffallback
#
Architecture
main.py: GUI, settings, thread orchestrationCaptureThread: Runs scrolling & screenshot logic on background thread- Image Similarity: Grayscale thumbnails compared to detect end of page
- PDF Export: Multi-page via Pillow or
img2pdffallback
#
How It Works
- Initial Delay: 3 seconds to switch focus to browser
- Scroll Loop:
- Grab full-screen screenshot
- Compare with previous (100×100 grayscale threshold)
- If similar beyond 95%, capture final part and exit
- Else, scroll down by configured height and repeat
- Signal UI:
screenshot_taken,status_update,capture_completesignals update progress
#
Configuration Parameters
#
Packaging as Executable
This project includes a PyInstaller spec (main.spec):
pip install pyinstaller
pyinstaller main.specLook under dist/ or build/ for the generated executable.
#
Troubleshooting
- Blank screenshots: Ensure browser window is not minimized and is in focus.
- OCR or hidden UI elements: Use headless capture libraries or adjust scroll offsets.
- Permission errors: On macOS, grant screen recording privileges.
- PDF Export fails: Install
img2pdfviapip install img2pdf.
#
FAQ
Q: Can I capture only part of a page?
A: Not currently; feature coming soon (scroll region selection).
Q: Why are some screenshots repeated?
A: Overlapping scroll height may cause repeats. Increase delay or adjust scroll height.
Q: How do I change similarity threshold?
A: Hardcoded to 0.95; modify images_are_similar() in CaptureThread.
#
Contributing
- Fork the repo
- Create a feature branch (
git checkout -b feature/YourFeature) - Commit your changes (
git commit -m 'Add feature') - Push to your branch (
git push origin feature/YourFeature) - Open a Pull Request
Please follow PEP8 and include tests for new functionality.