
#
ArcNews





GitHub: https://github.com/0xarchit/ArcNews-DashBoard/
Live Demo: https://arcnews.0xarchit.is-a.dev
Backend & Frontend Status: https://arcnewsapi.0xarchit.is-a.dev
#
Support This Project
If you find ArcNews useful for learning, prototyping, or as a reference, please consider starring the repository. Your support is greatly appreciated and helps the project's visibility.
#
Overview
ArcNews is a comprehensive, production-style news dashboard designed with a modular, full-stack architecture. It demonstrates the integration of multiple modern technologies to deliver a feature-rich user experience. The system is composed of four distinct, independently deployable services that work in concert:
-
Frontend: A responsive and interactive user interface built with Vite, React, and TypeScript. It handles user authentication, preferences, and the presentation of news articles. -
WorkerDBApi: The core backend service, built on Cloudflare Workers and the D1 database. It serves as the primary data source for the frontend, manages data ingestion, and orchestrates calls to other backend services. It refreshes after every 1 hour with the help of cronjobs. -
NewsAPI: A data-sourcing service written in Python with FastAPI. It is responsible for fetching and parsing news articles from various external RSS feeds and websites, normalizing the data for ingestion. -
ContentExtract: A specialized microservice using Node.js and Puppeteer. Its purpose is to extract the full, clean content from article URLs and generate concise summaries using an LLM.
Important
The WorkerDBApi uses Cloudflare Cron to refresh the D1 data roughly every hour. Ensure service URLs and D1 bindings are configured before deploying.
This document provides a deep dive into the project's architecture, the inner workings of each service, complete API documentation, and guides for local development and deployment.
#
Preview
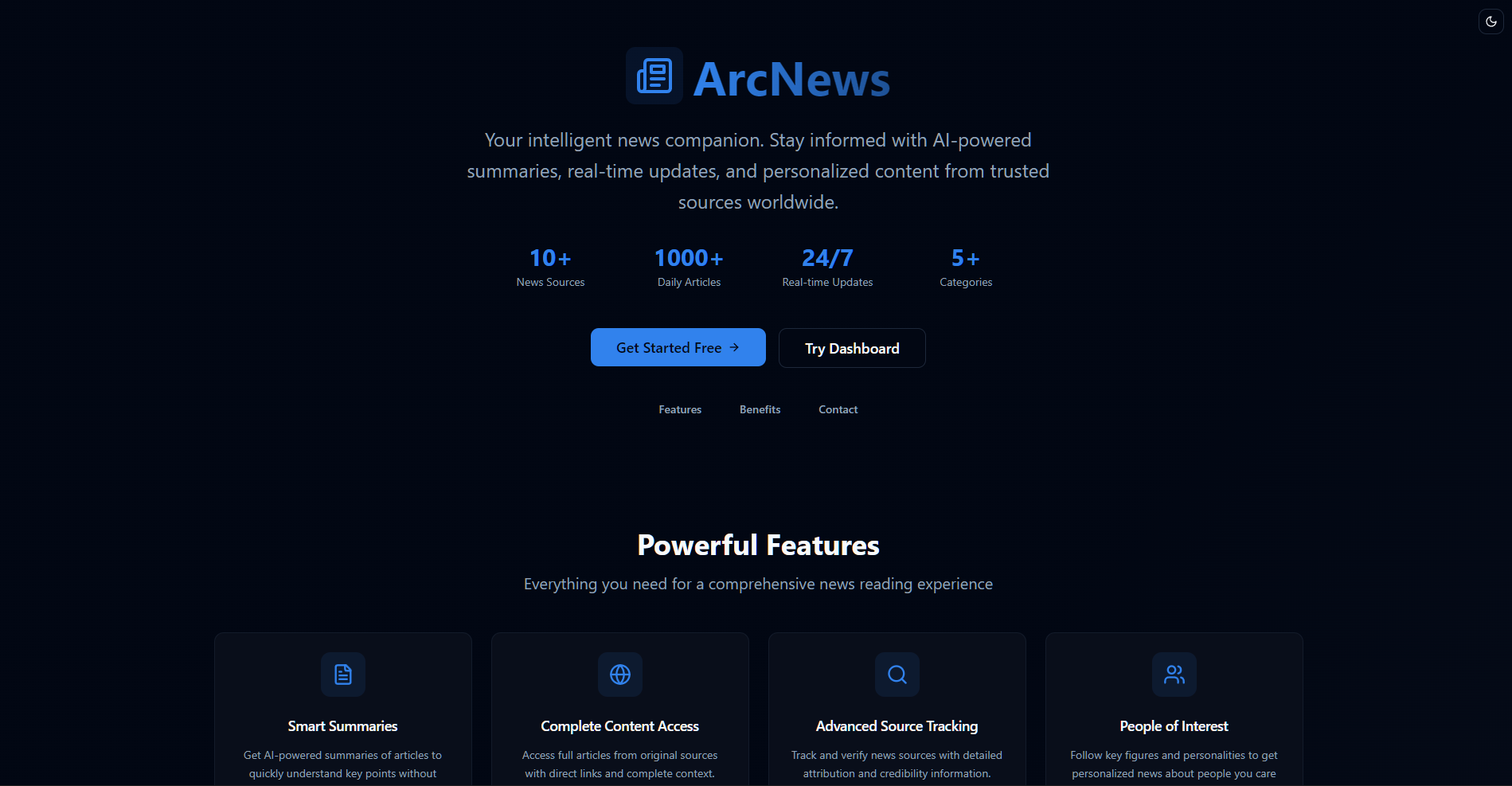
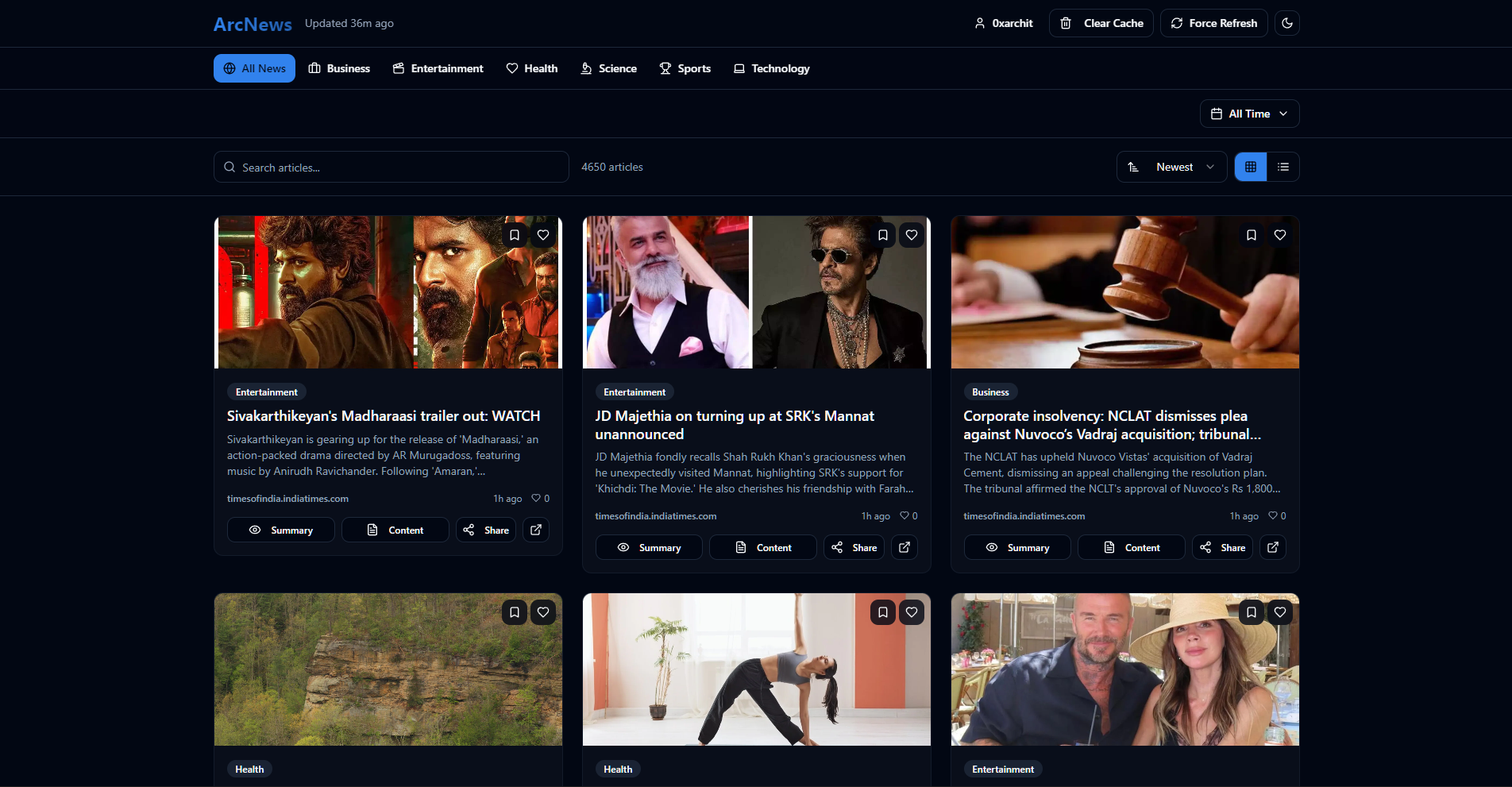
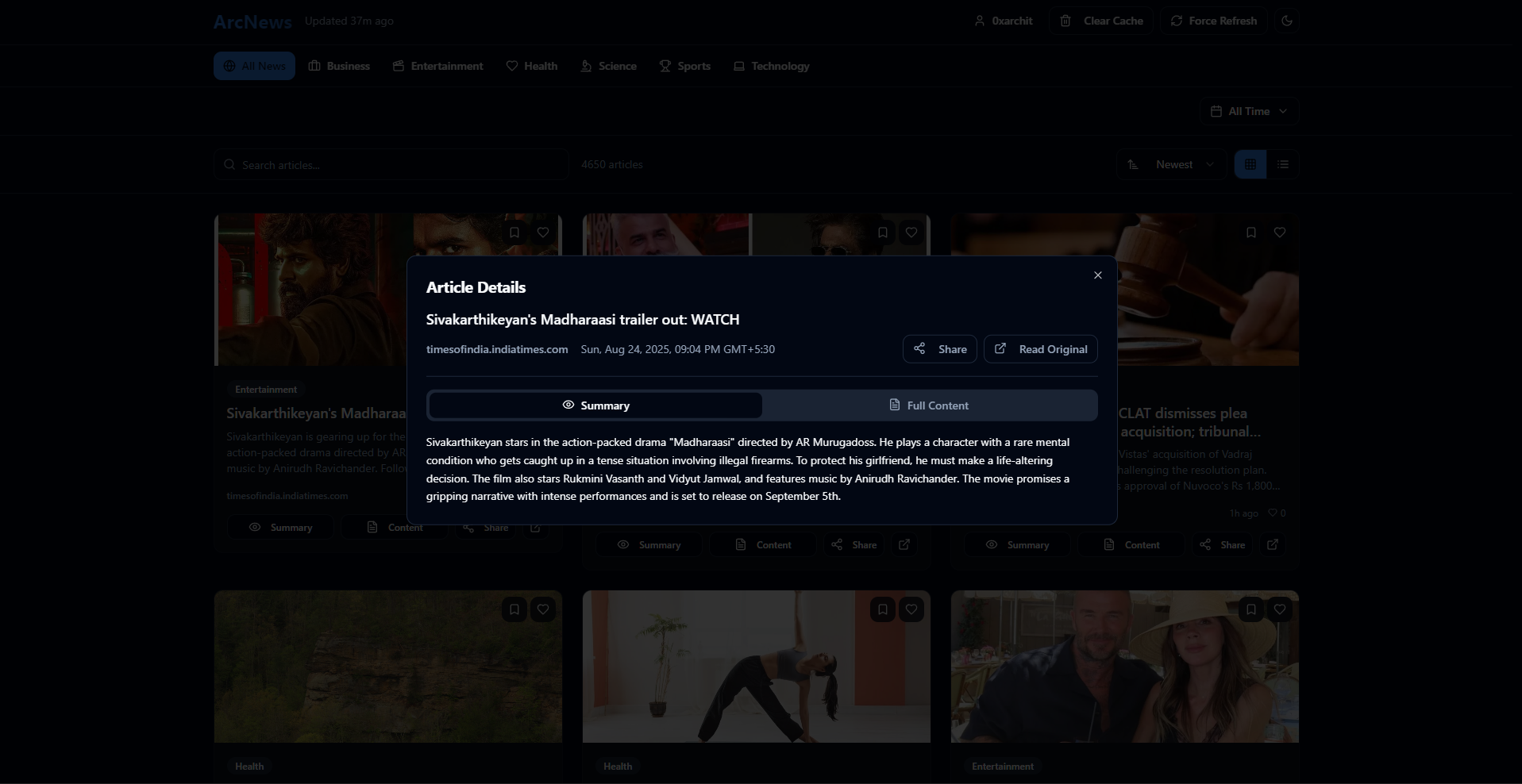
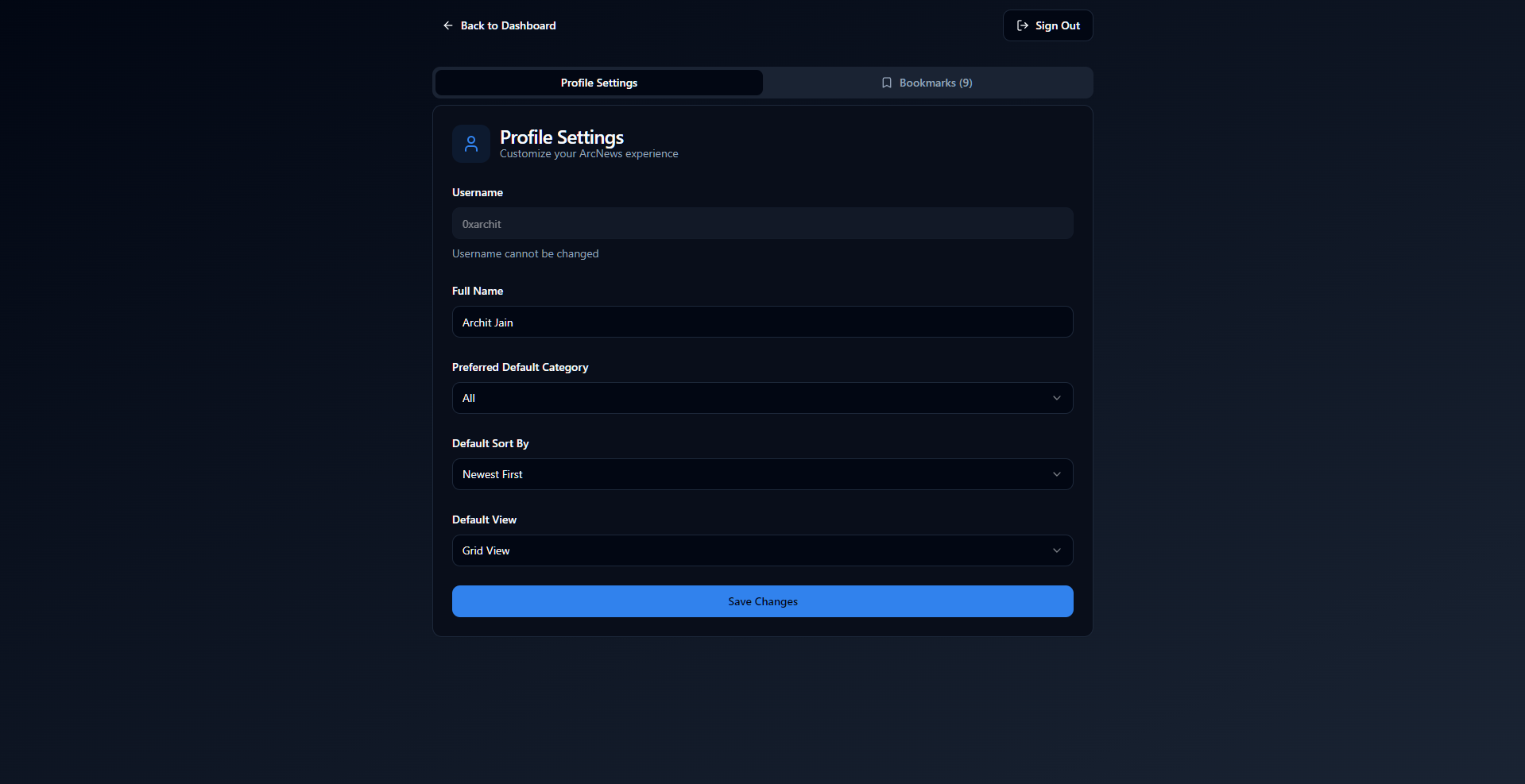
#
System Architecture
The architecture is designed for scalability and separation of concerns. The frontend is completely decoupled from the data sourcing and processing logic, communicating only with the core API worker and Supabase for user-specific data.
#
High-Level Diagram
This diagram illustrates the primary components and their interactions.
flowchart TB
subgraph "User Domain"
U[Browser]
end
subgraph "Frontend Service (Vercel/Netlify)"
FE[React + Vite + TS\nTailwind + ShadCN]
SB[(Supabase Auth + Bookmarks)]
end
subgraph "Core API (Cloudflare)"
WKR[WorkerDBApi Cloudflare Worker + D1 DB]
end
subgraph "Data Sourcing (Vercel/Heroku)"
NAPI[NewsAPI Python FastAPI Parsers]
end
subgraph "Content Processing (Fly.io/Render)"
CE[ContentExtract Node.js + Puppeteer + LLM]
end
U <--> FE
FE <--> SB
FE <--> WKR
WKR --> NAPI
WKR --> CE
Key Principles:
- Decoupled Frontend: The
Frontendonly communicates withWorkerDBApifor news data andSupabasefor authentication and bookmarks. It has no knowledge of the other backend services. - Orchestration Layer:
WorkerDBApiacts as the central orchestrator. It handles all server-to-server communication, shielding the frontend from the complexity of data ingestion and processing. - Scalable Microservices:
NewsAPIandContentExtractare independent services that can be scaled or replaced without impacting the rest of the system.
#
Data Flow: Article Ingestion (Scheduled)
This sequence shows how new articles are periodically fetched and stored.
sequenceDiagram
participant CRON as Cloudflare Cron
participant WKR as WorkerDBApi
participant NAPI as NewsAPI
participant D1 as D1 Database
CRON->>WKR: Trigger scheduled refresh
WKR->>NAPI: GET /{category}
NAPI-->>WKR: Returns normalized articles array
WKR->>D1: De-duplicate and UPSERT new articles
D1-->>WKR: Confirm writes
WKR->>D1: Prune articles older than 7 days
WKR->>WKR: Update 'last_refresh' timestamp in metadata
#
Data Flow: Summary Enrichment (On-Demand)
This sequence shows how an article's full content and summary are fetched the first time a user requests them.
sequenceDiagram
participant FE as Frontend
participant WKR as WorkerDBApi
participant CE as ContentExtract
participant D1 as D1 Database
FE->>WKR: GET /summary?category=tech&id=123
WKR->>D1: SELECT summary FROM tech WHERE id=123
alt Article already has a summary
D1-->>WKR: Returns summary
WKR-->>FE: 200 OK { article with summary }
else Summary is missing
D1-->>WKR: Returns NULL
WKR->>CE: POST /extract-content { url, title, ... }
CE-->>WKR: 200 OK { content, summary }
WKR->>D1: UPDATE tech SET summary=..., content=... WHERE id=123
WKR-->>FE: 200 OK { article with new summary }
end
#
Services In Depth
#
Frontend
The frontend is a modern, single-page application providing a seamless and dynamic user experience.
- Directory:
Frontend/ - Tech Stack:
- Framework: React 18 with Vite (SWC)
- Language: TypeScript
- UI: TailwindCSS with ShadCN UI components
- Icons:
lucide-react - Data Fetching: TanStack Query for server state,
axios - Routing:
react-router-dom - Authentication & Bookmarks:
@supabase/supabase-js
- Key Features:
- User Authentication: Secure sign-up, sign-in, and session management via Supabase Auth.
- Personalized Bookmarks: Users can save and manage their favorite articles, stored in a dedicated Supabase table.
- Dynamic Dashboard:
- Filter news by category (Tabs).
- Filter news by date range (Date Picker).
- Full-text search across all articles.
- Sort by date or popularity (likes).
- Multiple Views: Switch between responsive Grid and List layouts.
- Infinite Scroll: Smoothly loads more articles as the user scrolls.
- Article Modal: Displays the full, cleaned article content and AI-generated summary.
- Robust Caching:
- Category-based news data is cached in
localStoragefor 1 hour to reduce API calls. - The cache implementation is resilient, automatically handling
QuotaExceededErrorby evicting the oldest or largest entries to make space.
- Category-based news data is cached in
- Optimistic UI Updates: Bookmarking and liking articles provide immediate feedback while the request is in flight.
- Theme Persistence: Light, dark, and system theme support, saved to
localStorage. - Core Logic & Hooks:
hooks/useBookmarks.ts: A critical hook that manages bookmark state. It features a shared in-memory store with a 60-second TTL, in-flight promise de-duplication to prevent redundant fetches, and listeners to sync state across all components using the hook.utils/api.ts: Centralized API client for interacting with theWorkerDBApi. It uses theVITE_API_BASE_URLand includes afetchWithTimeoututility.utils/cache.ts: Implements the robustlocalStoragecaching logic with TTL and intelligent eviction.
- Environment Variables (
Frontend/.env):
# The URL of your Supabase project
VITE_SUPABASE_URL="https://<project-id>.supabase.co"
# The public anonymous key for your Supabase project
VITE_SUPABASE_PUBLISHABLE_KEY="<your-public-anon-key>"
# The URL of your deployed WorkerDBApi
VITE_API_BASE_URL="https://worker-url.workers.dev"- Supabase Schema (
public.bookmarks):
CREATE TABLE public.bookmarks (
id uuid PRIMARY KEY DEFAULT gen_random_uuid(),
user_id uuid NOT NULL REFERENCES auth.users(id) ON DELETE CASCADE,
article_id INTEGER NOT NULL,
article_category TEXT NOT NULL,
article_title TEXT NOT NULL,
article_source TEXT NOT NULL,
article_url TEXT NOT NULL,
article_image_url TEXT,
article_published_at TEXT NOT NULL,
created_at TIMESTAMPTZ DEFAULT now() NOT NULL
);
-- Indexes for efficient querying
CREATE INDEX idx_bookmarks_user_created ON public.bookmarks(user_id, created_at DESC);
CREATE INDEX idx_bookmarks_user_article ON public.bookmarks(user_id, article_id, article_category);
-- Enable Row Level Security
ALTER TABLE public.bookmarks ENABLE ROW LEVEL SECURITY;
-- RLS Policies
CREATE POLICY "Users can view their own bookmarks" ON public.bookmarks
FOR SELECT USING (auth.uid() = user_id);
CREATE POLICY "Users can insert their own bookmarks" ON public.bookmarks
FOR INSERT WITH CHECK (auth.uid() = user_id);
CREATE POLICY "Users can delete their own bookmarks" ON public.bookmarks
FOR DELETE USING (auth.uid() = user_id);
#
WorkerDBApi
This is the heart of the backend, handling data persistence, orchestration, and serving all content to the frontend.
- Directory:
WorkerDBApi/ - Technology: Cloudflare Workers + D1 Database
- Core Responsibilities:
- Data Ingestion: On a cron schedule (
scheduledhandler), it fetches new articles fromNewsAPI. - Data Persistence: Stores and manages news articles in separate D1 tables for each category.
- API Gateway: Exposes a public API for the frontend.
- Service Orchestration: Calls
ContentExtracton-demand to enrich articles with summaries. - Business Logic: Manages like counts and user interactions with articles.
- Data Ingestion: On a cron schedule (
- D1 Database Schema:
- A separate table is created for each news category (e.g.,
technology,sports, etc.).
- A separate table is created for each news category (e.g.,
CREATE TABLE technology (
id INTEGER PRIMARY KEY,
title TEXT,
description TEXT,
url TEXT UNIQUE,
urlToImage TEXT,
publishedAt TEXT,
summary TEXT,
content TEXT,
likes INTEGER DEFAULT 0,
liked_by TEXT -- Stores a JSON array of usernames as a string
);- A metadata table tracks system state. CREATE TABLE metadata (
key TEXT PRIMARY KEY,
value TEXT,
last_refresh TEXT
);- Configuration (
wrangler.tomlandworker.js):- You must bind a D1 database in
wrangler.toml. - Placeholders in
worker.jsmust be replaced with your deployed service URLs:newsApiUrl: The base URL for yourNewsAPIservice. The worker appends the category to it (e.g.,https://my-news-api.vercel.app/technology).'add extract url': The full URL for yourContentExtractservice's/extract-contentendpoint.
- You must bind a D1 database in
#
ewsAPI
This service acts as the data provider, abstracting the complexity of fetching and parsing from various news sources.
- Directory:
NewsAPI/ - Technology: Python 3.11+ with FastAPI
- Core Logic:
- For each category, it maintains a list of RSS feeds or websites.
- It uses libraries like
feedparserandregexto handle different data formats. - It normalizes the extracted data into a consistent
NewsItemschema before returning it. - The provided
index.pyis a functional scaffold; the parsing logic within each function needs to be fully implemented and dependencies (feedparser, etc.) installed.
- CORS: Configured to only allow requests from the deployed
WorkerDBApiorigin for security.
#
ContentExtract
A powerful microservice dedicated to turning a URL into clean, readable content and a summary.
- Directory:
ContentExtract/ - Technology: Node.js with Express,
puppeteer-extra(with stealth plugin),@mozilla/readability, andaxios. - Core Logic:
- Receives a
POSTrequest with a URL. - Launches a headless Chromium browser using Puppeteer. The stealth plugin helps bypass bot detection.
- Intercepts network requests to block images, ads, and trackers for speed and cleanliness.
- Navigates to the URL and extracts the raw HTML.
- Uses Mozilla's
Readabilitylibrary to parse the HTML and extract the main article content, stripping away sidebars, headers, and other clutter. - If Readability fails, it falls back to common selectors (
main,article). - The cleaned text is sent to an LLM endpoint (e.g., OpenAI-compatible API) with a prompt to summarize it.
- Returns the original URL, title, description, full cleaned content, and the generated summary.
- Receives a
#
Detailed API Reference
#
WorkerDBApi Endpoints
This is the public API consumed by the Frontend.
- Base URL:
https://example.workers.dev(or your deployment) - Common Headers:
Content-Type: application/json,Access-Control-Allow-Origin: *
GET /{category}
- Path Parameter:
categorymust be one ofbusiness,entertainment,health,science,sports,technology. - Success (200):
{
"status": "ok",
"totalResults": 150,
"articles": [
{
"id": 101,
"source": "wired.com",
"title": "The Future of AI",
"description": "A look into the next decade...",
"url": "https://www.wired.com/story/future-of-ai",
"urlToImage": "https://...",
"publishedAt": "2025-08-22T10:05:00.000Z",
"summary": "",
"content": "",
"likes": 15,
"liked_by": ["user1", "user2"]
}
]
}
```
- **Error (500)**: If the database query fails.
---
**`GET /summary`**
- **Query Parameters**:
- `category` (string, required)
- `id` (integer, required)
- **Success (200)**:
```json
{
"id": 101,
"source": "wired.com",
"title": "The Future of AI",
"summary": "This article explores the rapid advancements in artificial intelligence...",
"content": "The full, cleaned text of the article...",
"likes": 15,
"liked_by": ["user1", "user2"]
}- Errors:
400 Bad Request: Ifcategoryoridare missing or invalid.404 Not Found: If no article with that ID exists in the category.500 Internal Server Error: If the database or theContentExtractservice fails.
#
ContentExtract Endpoints
Server-to-server API consumed by WorkerDBApi.
- Base URL:
http://localhost:3000(or your deployment)
POST /extract-content
- Request Body:
{
"url": "https://www.wired.com/story/future-of-ai",
"title": "The Future of AI",
"description": "A look into the next decade..."
}
```
- **Success (200)**:
```json
{
"url": "https://www.wired.com/story/future-of-ai",
"title": "The Future of AI",
"description": "A look into the next decade...",
"content": "The full, cleaned text of the article...",
"summary": "This article explores the rapid advancements in artificial intelligence..."
}- Errors:
400 Bad Request: Ifurlis missing or invalid.500 Internal Server Error: If Puppeteer or the LLM call fails.
#
NewsAPI Endpoints
Server-to-server API consumed by WorkerDBApi.
- Base URL: Your deployment (e.g., on Vercel)
GET /{category}
- Path Parameter:
category(e.g.,technology,sports). Success (200): Returns a raw JSON array of normalized article objects.
[ { "title": "New Breakthrough in Quantum Computing", "link": "https://www.example.com/quantum-breakthrough", "pubdate": "2025-08-22T12:00:00Z", "description": "Scientists have announced a major leap...", "thumbnail_url": "https://...", "category": "technology" } ]
#
Local Development
#
Prerequisites
- Node.js (v18 or newer)
pnpm(for Frontend)- Python (v3.11 or newer)
- Cloudflare Wrangler CLI
#
Setup Instructions
- Clone the repository:
git clone https://github.com/0xarchit/ArcNews-DashBoard.git
cd ArcNews-DashBoard- Frontend:
cd Frontend
pnpm install
cp .env.example .env # Create .env from example
# Fill in your VITE_SUPABASE_URL, VITE_SUPABASE_PUBLISHABLE_KEY, and VITE_API_BASE_URL
pnpm dev- ContentExtract:
cd ContentExtract
npm install
npm start- NewsAPI:
cd NewsAPI
pip install -r requirements.txt
uvicorn api.index:app --reload- WorkerDBApi:
cd WorkerDBApi
npm install
# Configure wrangler.toml with your account_id and D1 binding
# Create the D1 database: wrangler d1 create <db-name>
# Run the schema: wrangler d1 execute <db-name> --file=./schema.sql
# Update placeholders in worker.js to point to your local NewsAPI and ContentExtract services
wrangler dev
#
Deployment
- Frontend: Deploy to a static host like Vercel or Netlify. Set the environment variables in the project settings.
- WorkerDBApi: Deploy to Cloudflare Workers. Create a D1 database and bind it. Set the URLs for the deployed
NewsAPIandContentExtractservices as secrets.
Note
For Cloudflare Workers, ensure wrangler.toml has your account_id, the D1 binding, and environment vars for service URLs.
- NewsAPI: Deploy to a serverless function provider like Vercel or Heroku.
- ContentExtract: Deploy to a service that supports long-running Node.js processes and can run headless Chrome, such as Fly.io or Render.
#
Future Goals
- Google One‑Tap / Social Sign‑In: add Google One‑Tap and additional OAuth providers (Apple, Twitter) for frictionless, secure sign-in and streamlined account linking.
- Enhanced performance & UX: implement server-side caching, CDN edge caching, D1 query optimizations, image lazy‑loading and HTTP/2 to reduce TTFB and improve perceived load times.
- Broader source coverage: expand NewsAPI feed lists to include more mainstream outlets, niche blogs, podcasts, and paid/partner APIs with adaptive scraping strategies and source weighting.
- Richer summarization pipeline: support configurable LLM backends, hybrid extractive+abstractive summaries, length presets, and cached summary versions to reduce costs and latency.
- Personalization & recommendations: per‑user topic preferences, collaborative filtering, session‑based ranking, and push personalization signals to deliver more relevant headlines.
- Offline & sync support: add PWA capabilities, background sync, and local read‑later queues so users can read saved articles offline.
- Real‑time updates & notifications: web push and in‑app notifications for breaking news, followed topics, and bookmark/like activity.
- Multi‑language & localization: automatic language detection, on‑the‑fly translation, localized UI strings, and right‑to‑left support where required.
- Accessibility & SEO improvements: audit and remediate WCAG issues, improve semantic markup, and enhance metadata for social previews and indexing.
- Fact‑checking & content quality signals: integrate source reliability scores, third‑party fact‑check APIs, and community reporting flows to surface trustworthy content.
- AI Chatbot Integration: Implement an AI-powered chatbot to enable users to discuss news topics, ask questions, and verify the credibility of articles using integrated fact-checking APIs and source reliability data.
- Monetization & community: non‑intrusive monetization (sponsorships, donations, premium features, non irritating ads placements), contribution guidelines, and curated editorial channels to build a community around the project.
#
Troubleshooting
-
QuotaExceededErrorin Browser: This is handled automatically by the frontend's cache eviction logic. If it persists, the user'slocalStorageis completely full. - Bookmark Failures: Check the browser's developer console for errors from Supabase. Ensure the user is logged in and RLS policies are correct.
- Missing Summaries: Verify that the
WorkerDBApican reach theContentExtractservice. Check the worker logs for any errors. - Data Not Refreshing: Ensure the
WorkerDBApicron job is enabled and that it can reach theNewsAPIservice. Check the logs for both services.